四种遍历
先序、中序、后序遍历,非常简单!接下来我会用一种通用的方式完成这三种遍历哟!
保证你看完能迅速手写三种遍历的非递归!先序遍历
递归
1 | class Solution { |
非递归
1 | /** |
Tip: 我这里再拓展一种非递归的想法吧…但是我觉得这种想法不是很好,没有通用的非递归思想简单!强烈建议使用上面的非递归思想!!!
至于为何非要提这种思想捏,原因就是 栈 如果换成 队列,左右节点顺序调一下,就是层序遍历了!
思想:
- 上面的非递归的做法是把一棵树看做只有根节点和右节点,先全部把根节点读完了,再去读其右节点,这样也就做到了 根 - 左 - 右
- 下面要讲的非递归的做法是 先读根节点,然后将其加入栈,然后只要栈非空,就弹栈,将其加入需要返回的列表中,然后先将其右子树节点加入到栈中,然后将左子树节点加入到栈中,注意,这里是先右子树,后左子树,因为栈是后进先出!下一步就是左子树出栈,将其加入列表中。
1 | class Solution { |
中序遍历
递归
1 | class Solution { |
非递归
1 | private List<Integer> inorderTraversalByIteration(TreeNode root) { |
后序遍历
递归
1 | class Solution { |
非递归
后序非递归相对前两个遍历的非递归需要一个小技巧!
后序是 左 - 右 - 根,反过来就是根 - 右 - 左,那其实跟先序基本就一模一样了,先序是根 - 左 - 右,所以只需要在先序的非递归中 改两行代码 + 加一行代码 就完成了!
1 | private List<Integer> postorderTraversalByIteration(TreeNode root){ |
层序遍历
层序是不是还有一个名字 叫 BFS
递归
这个竟然时间和空间击败了100%的人… 莫名有点开心啊
1 | public List<List<Integer>> levelOrder(Node root) { |
非递归
上面讲了一种用队列实现的非递归思想
1 | public static List<Integer> levelOrder(TreeNode root) { |
1 | /** |
相关题型
二叉树的右视图
题目
给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例:
1 | 输入: [1,2,3,null,5,null,4] |
思路
- 层序遍历 BFS。先写出双重 list 的层序遍历,然后在每一个内层list中拿到最后一个值即可;
- 深度遍历 DFS。递归 DFS,从右向左,拿到第一个数即可。
实现
- BFS
1 | /** |
- DFS
1 | class Solution { |
对称二叉树
题目
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 | 1 |
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 | 1 |
思路
- 先讲一下自己的思路: 利用层序非递归,用双层List存储树的节点,每一层存入一个单层List中,然后单层List可以采用二分判断是否对称!
- 答案思路:树的复制,这个想法很nice!复制原树,判断其左子树节点是否和右子树节点相同且判断其左子树的左是否等于右子树的右,左子树的右是否等于右子树的左。在非递归的写法中,树的复制这种思想体现的更加明显,这个就是典型的用空间换时间!
实现
- 树复制思想之递归
1 | /** |
- 树复制之非递归
所以这里使用了Queue的另外一个实现类LinkedList,它也是非线程安全的哟,但是可以存储null!!!
1 | private static boolean isSymmetricByIteration(TreeNode root){ |
- 层序非递归
1 | /** |
二叉树的最大深度
吖!这个是二叉树最简单的题目了吧…但是绝对是一道经典好题!下面将用最常用的三种方法解决它!
题目
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
思路
- 方法一:递归。这个我在另外一篇递归中的文章中有提到,可以一行代码解决哟!
- 方法二:层序遍历。即用BFS解决,每遍历完一层就记录深度。
- 方法三:DFS。用栈实现即可。(还学到Pair这玩意…为何我以前都不知道)
实现
- 递归
- 1、找出口,节点为空即可退出递归。
- 2、找返回值,返回的是该节点所在层的深度。
- 3、确定一次递归需要做什么。当前节点深度 = 子节点最大深度 + 1。
1 | class Solution { |
- BFS
层序非递归遍历,稍微改写一下就好了,这里不需要存储节点,所以只需要用一个值来记录深度即可。
第一种非递归方式改写1 | import javafx.util.Pair; |
1 | /** |
- DFS
其实就是在先序非递归的基础上稍加改动,压栈的不再只是节点,还包括了节点的深度,用Pair类型存储!
1 | import javafx.util.Pair; |
二叉树的最小深度
题目
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
返回它的最小深度 2。
思路
- BFS,套用 BFS 模板。
代码
1 | class Solution { |
路径总和「根到叶子节点」是否等于目标和
题目
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
思路
- 递归。我都递归的要吐了,二叉树日常递归!
- DFS,自己建栈模拟递归。
实现
- 递归 1
(三元表达式纯粹装逼哈哈哈)
1 | class Solution { |
- 递归 2
1 | public boolean hasPathSum(TreeNode root,int sum){ |
- DFS
我觉得思想都很简单啊,其实二叉树的基本上所有的题目都是建立在前序和层序遍历的基础上的,熟练掌握了前序和层序的递归非递归就基本能解所有题目了…
(在前序非递归的基础上稍加改动就行了…)
1 | import javafx.util.Pair; |
求根节点到叶节点数字之和
题目
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字
- 例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
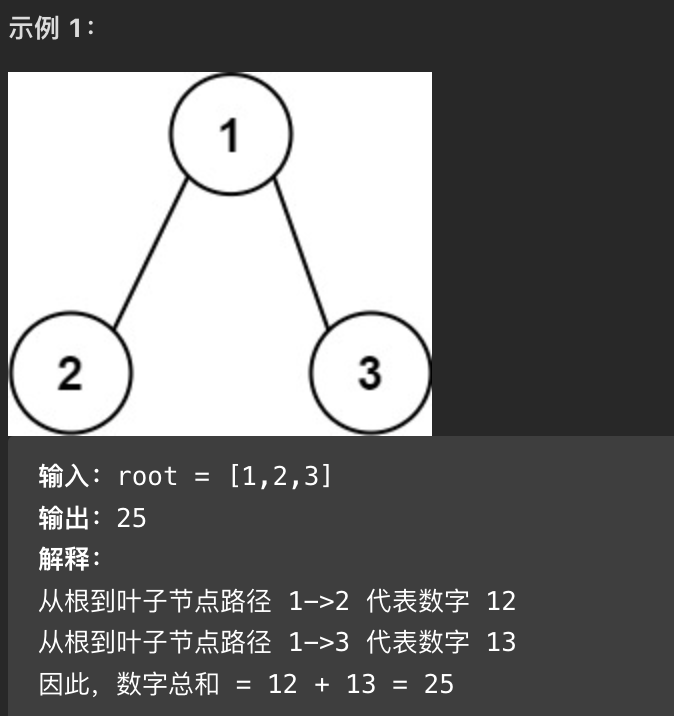
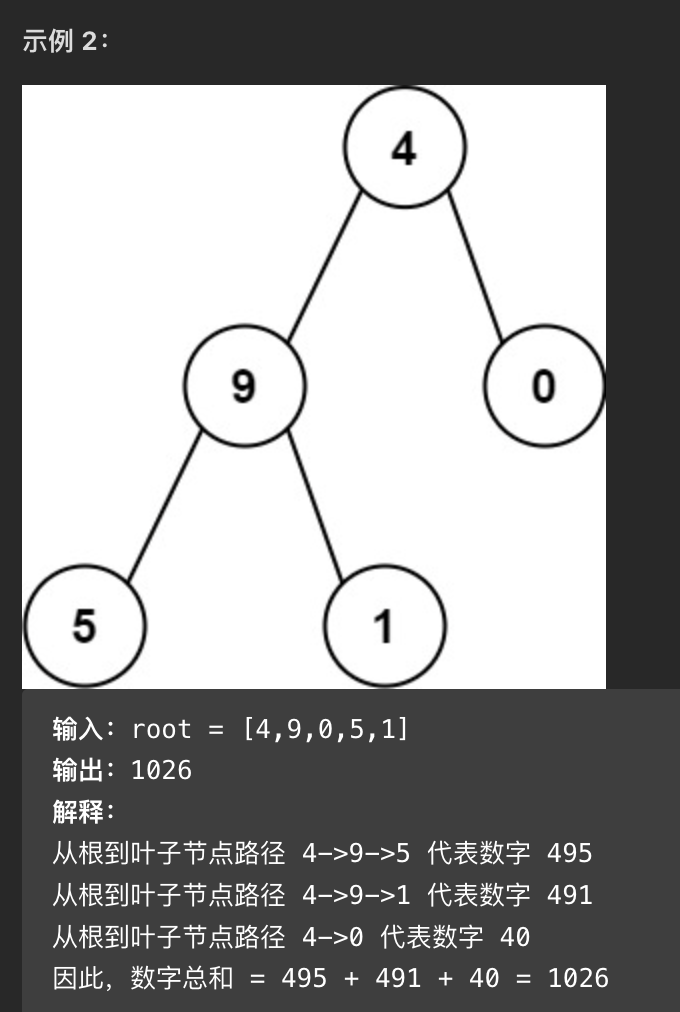
思路
dfs:从根节点开始,遍历每个节点,如果遇到叶子节点,则将叶子节点对应的数字加到数字之和。如果当前节点不是叶子节点,则计算其子节点对应的数字,然后对子节点递归遍历
- 时间复杂度 O(n),n为二叉树节点个数
- 空间复杂度 O(n),最坏情况下,二叉树高度等于节点个数,递归深度最多为 n
bfs:需要维护两个队列,分别存储节点和节点对应的数字。
- 初始时,将根节点和根节点的值分别加入两个队列。每次从两个队列分别取出一个节点和一个数字,进行如下操作:
- 如果当前节点是叶子节点,则将该节点对应的数字加到数字之和;
- 如果当前节点不是叶子节点,则获得当前节点的非空子节点,并根据当前节点对应的数字和子节点的值计算子节点对应的数字,然后将子节点和子节点对应的数字分别加入两个队列。
- 搜索结束后,即可得到所有叶子节点对应的数字之和。
- 时间复杂度 O(n),同 dfs
- 空间复杂度 O(n),取决于队列长度,队列元素个数不会超过 n
代码
- dfs
1 | class Solution { |
- bfs
1 | class Solution { |
求从根节点到叶子节点的最大值
题目
二叉树从根节点到叶子节点的最长路径
思路
上题稍微改一下就好啦,加个 max,记录一下。
代码
1 | public static void main(String[] args) { |
二叉树的直径
题目
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过根结点。
示例 :
给定二叉树
1 | 1 |
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
注意:两结点之间的路径长度是以它们之间边的数目表示。
思路
按照常用方法计算一个节点的深度:max(depth of node.left, depth of node.right) + 1。在计算的同时,经过这个节点的最大直径为 (depth of node.left) + (depth of node.right) 。搜索每个节点并记录这些路径经过的点数最大值,期望长度是就是结果。
代码
1 | class Solution { |
二叉树的最大路径和
题目
给定一个非空二叉树,返回其最大路径和。
本题中,路径被定义为一条从树中任意节点出发,达到任意节点的序列。该路径至少包含一个节点,且不一定经过根节点。
示例 1:
1 | 输入: [1,2,3] |
思路
这题还是挺难的,要求最大路径和,可以采用递归,递归就是三部曲:
1、确定递归出口,这个简单,root == null 即退出
2、确定返回值,这个是本题最难的,返回的是以该节点结尾的最大路径和!!!
3、一级递归需要做的事,其实就是去算最大的路径和,这个很简单,在二叉树中,一级递归其实也就是三个节点,分别是根节点,左子树节点,右子树节点,既然每个节点返回的是 以该节点结尾的最大路径和,则我们可以在每级递归时去更新一下最大的路径和,即 左子树节点返回来的以其节点结尾的最大路径和 + 根节点的值 + 右子树节点返回的以该节点结尾的最大路径和。
代码
1 | class Solution { |
从中序与后序遍历序列构造二叉树
题目
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
1 | 中序遍历 inorder = [9,3,15,20,7] |
返回如下的二叉树:
1 | 3 |
思路
我写的应该比较简洁,参数少的原因是抓住了后序是左--右--根的特点,所以后序遍历从后向前是根--右--左,故在递归时根本没有必要将后序遍历的数组界限传入,每次有节点加入就自减一就行,只要满足了先拿到根节点然后遍历右子树,再遍历左子树这个原则就Okay。
至于递归如何写,其实把握三个原则就行:
递归出口,这里就不解释了
每次递归的返回值,这里很明显就是题目要求的root节点
单次递归需要做的事,我们需要构建一个树,那么单次递归就是拿到根节点,并且指向正确的左右子树即可。
代码
1 | class Solution { |
从前序与中序遍历序列构造二叉树
题目
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
1 | 前序遍历 preorder = [3,9,20,15,7] |
返回如下的二叉树:
1 | 3 |
思路
跟上面的思路一致,就是刚好相反而已嘛…
代码
1 | class Solution { |
填充每个节点的下一个右侧节点指针
题目
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
1 | struct Node { |
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:

思路
最简单的思路:层序遍历,分别获得每层的节点,然后生成链表,所以这个不是完美二叉树也可以做,也就是说没有用到 完全二叉树 的性质!所以必定不是最优解!而且这个使用的不是常量级的空间,其实是不太符合要求的。
(看了答案的)高赞的 拉拉链解法,将一棵大的二叉树一分为二,处理两棵小二叉树的连接,再递归解决小二叉树内部连接。
还有一种非递归的方法,个人觉得也是非常的精妙,之前我们是用列表保存每一层的节点,其实这是一种浪费。只需要解决三个问题就够了。参考网址
- 每一层怎么遍历?
之前是用队列将下一层的节点保存了起来。
这里的话,其实只需要提前把下一层的next构造完成,到了下一层的时候就可以遍历了。
- 什么时候进入下一层?
之前是得到当前队列的元素个数,然后遍历那么多次。
这里的话,注意到最右边的节点的next为null,所以可以判断当前遍历的节点是不是null。
- 怎么得到每层开头节点?
之前队列把当前层的所以节点存了起来,得到开头节点当然很容易。
这里的话,我们额外需要一个变量把它存起来。
三个问题都解决了,就可以写代码了。利用三个指针,start指的是当前层的最左节点,也就是本层的起点,cur指的是当前正在遍历的节点,cur.next指的是正在遍历的节点的下一个节点!我觉得这个方法最难想的就是 在遍历本层的时候,将下层的next构造完成!!!
- 每一层怎么遍历?
代码
- 方法一:层序遍历
1 | /** |
- 方法二:拉拉链法
1 | /** |
- 方法三:非递归解法(个人最推荐的做法)
1 | /** |
填充每个节点的下一个右侧节点指针 II
题目
给定一个二叉树
1 | struct Node { |
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
进阶:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
示例:

1 | 输入:root = [1,2,3,4,5,null,7] |
提示:
- 树中的节点数小于
6000 -100 <= node.val <= 100
思路
方法一:上一题已经讲过,依旧可以用上面的代码,BFS。
方法二:题目要求只能使用常量级额外空间,意味着其实严格上不能使用队列,那怎么做呢?
可以使用一个尾指针,将所有的节点连接起来,刚好就是题目的next指针,可以做到这一点,至于每一层如何开始,只需要再引入一个指针进行标记即可,不同于BFS的是,BFS在遍历当前层时,是处理当前层的横向连接,并且将子节点加入队列中以便下一次的遍历,而方法二则是在每次循环时,直接处理下一层节点的横向连接问题,因为我并不知道每一层的节点数量和具体位置(无法保存),只能是如果该层下的子节点存在,就将他们连接!
1
2
3
4
5
6
7
8
9
10
11cur 指针利用 next 不停的遍历当前层。
如果 cur 的孩子不为 null 就将它接到 tail 后边,然后更新tail。
当 cur 为 null 的时候,再利用 dummy 指针得到新的一层的开始节点。
dummy 指针在链表中经常用到,他只是为了处理头结点的情况,它并不属于当前链表。
作者:windliang
链接:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by-28/
来源:力扣(LeetCode)
代码
- 方法一:同上(略)
- 方法二:
1 | public Node connectII(Node root){ |
二叉树的最近公共祖先
题目
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]

示例 1:
1 | 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 |
示例 2:
1 | 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 |
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
思路
注意p,q必然存在树内, 且所有节点的值唯一!!!
递归思想,对以root为根的(子)树进行查找p和q,如果root == null || p || q 直接返回root
表示对于当前树的查找已经完毕,否则对左右子树进行查找,根据左右子树的返回值判断:
- 左右子树的返回值都不为null, 由于值唯一左右子树的返回值就是p和q, 此时root为LCA
- 如果左右子树返回值只有一个不为null, 说明只有p和q存在于左或右子树中, 最先找到的那个节点为LCA
- 左右子树返回值均为null, p和q均不在树中, 返回null
代码
1 | class Solution { |
二叉树的序列化与反序列化
题目
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例:
1 | 你可以将以下二叉树: |
提示: 这与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
说明: 不要使用类的成员 / 全局 / 静态变量来存储状态,你的序列化和反序列化算法应该是无状态的。
思路
这题做了两个小时…还没整出来…思路其实特别的简单,就是用层序遍历,将所有结点存入列表中(包括了空节点),然后转成字符串,字符串再转成列表然后建立树
卡在建立树这块…心态有点炸…冷静会代码
1 | public class Codec { |
翻转二叉树
题目
翻转一棵二叉树。
示例:
输入:
4
/ \
2 7
/ \ / \
1 3 6 9
输出:
4
/ \
7 2
/ \ / \
9 6 3 1
思路
递归…注释有说
代码
1 | /** |
合并二叉树
题目
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
1 | 输入: |
注意: 合并必须从两个树的根节点开始。
思路
使用递归。我们可以对这两棵树同时进行前序遍历,并将对应的节点进行合并。在遍历时,如果两棵树的当前节点均不为空,我们就将它们的值进行相加,并对它们的左孩子和右孩子进行递归合并;如果其中有一棵树为空,那么我们返回另一颗树作为结果;如果两棵树均为空,此时返回任意一棵树均可(因为都是空)。
代码
1 | /** |
验证二叉搜索树
题目
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
思路
中序遍历
代码
1 | class Solution { |
把二叉搜索树转换为累加树
题目
给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和。
例如:
1 | 输入: 二叉搜索树: |
思路
二叉搜索树,第一想法就是用中序递归去做,累加树的意思是 根节点的值 = 根节点的值 + 右子树的值 ,然后再更新左子树的值 = 根节点的值 + 左子树的值,所以就符合右中左的遍历顺序,只要写出来右中左的递归,然后用一个全局变量记录上一个遍历的节点的值再加上本身的值,就okay了!
代码
1 | class Solution { |
Tip: 其实个人觉得这个题目有问题,既然是累加树,为何是按照右中左的遍历顺序来累加呢…我的根节点还得加到我左子树的最右叶子节点上!真的荒唐啊…
二叉树展开为链表
题目
给定一个二叉树,原地将它展开为链表。
例如,给定二叉树
1 | 1 |
将其展开为:
1 | 1 |
思路
注意题目的要求是 原地 展开!
这里强推一手题解里一位大佬写的!总共3个大方法,非常好!!!
解法一[自顶向下非递归]
可以发现展开的顺序其实就是二叉树的先序遍历。算法和 94 题中序遍历的 Morris 算法有些神似。
- 将左子树插入到右子树的地方
- 将原来的右子树接到左子树的最右边节点
代码的话也很好写,首先我们需要找出左子树最右边的节点以便把右子树接过来。
1 | public void flatten(TreeNode root) { |
解法二[自顶向上,推荐]
题目中,要求说是 in-place,之前一直以为这个意思就是要求空间复杂度是 O(1)。偶然看见评论区大神的解释, in-place 的意思可能更多说的是直接在原来的节点上改变指向,空间复杂度并没有要求。所以这道题也可以用递归解一下。利用变形的后序遍历 右左根即可。
1 | private TreeNode pre = null; |
相应的左孩子也要置为 null,同样的也不用担心左孩子丢失,因为是后序遍历,左孩子已经遍历过了。和 112 题一样,都巧妙的利用了后序遍历。
既然后序遍历这么有用,利用 112 题介绍的后序遍历的迭代方法,把这道题也改一下吧。
1 | public void flatten(TreeNode root) { |
解法三[自顶向上]
解法二中提到如果用先序遍历的话,会丢失掉右孩子,除了用后序遍历,还有没有其他的方法避免这个问题。在 Discuss 又发现了一种解法。
为了更好的控制算法,所以我们用先序遍历迭代的形式,正常的先序遍历代码如下,
1 | public static void preOrderStack(TreeNode root) { |
还有一种特殊的先序遍历,提前将右孩子保存到栈中,我们利用这种遍历方式就可以防止右孩子的丢失了。由于栈是先进后出,所以我们先将右节点入栈。
1 | public static void preOrderStack(TreeNode root) { |
之前我们的思路如下:
题目其实就是将二叉树通过右指针,组成一个链表。
1 | 1 -> 2 -> 3 -> 4 -> 5 -> 6 |
我们知道题目给定的遍历顺序其实就是先序遍历的顺序,所以我们可以利用先序遍历的代码,每遍历一个节点,就将上一个节点的右指针更新为当前节点。1
2
3
4
5先序遍历的顺序是 1 2 3 4 5 6。
遍历到 2,把 1 的右指针指向 2。1 -> 2 3 4 5 6。
遍历到 3,把 2 的右指针指向 3。1 -> 2 -> 3 4 5 6。
因为我们用栈保存了右孩子,所以不需要担心右孩子丢失了。用一个 pre 变量保存上次遍历的节点。修改的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public void flatten(TreeNode root) {
if (root == null){
return;
}
Stack<TreeNode> s = new Stack<TreeNode>();
s.push(root);
TreeNode pre = null;
while (!s.isEmpty()) {
TreeNode temp = s.pop();
/***********修改的地方*************/
if(pre!=null){
pre.right = temp;
pre.left = null;
}
/********************************/
if (temp.right != null){
s.push(temp.right);
}
if (temp.left != null){
s.push(temp.left);
}
/***********修改的地方*************/
pre = temp;
/********************************/
}
}
总结
解法一和解法三可以看作自顶向下的解决问题,解法二可以看作自底向上。以前觉得后序遍历比较麻烦,没想到竟然连续遇到了后序遍历的应用。先序遍历的两种方式自己也是第一次意识到,之前都是用的第一种正常的方式。
作者:windliang
链接:https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by--26/
Tips: 这个大佬写的是真好!
深度和广度优先搜索
BFS
框架
1 | // 计算从起点 start 到终点 target 的最近距离 |
队列 q 存储当前需要遍历的节点,BFS 的核心数据结构;cur.adj() 泛指 cur 相邻的节点,比如说二维数组中,cur 上下左右四面的位置就是相邻节点;visited 的主要作用是防止走回头路,大部分时候都是必须的,但是像一般的二叉树结构,没有子节点到父节点的指针,不会走回头路就不需要 visited。

